w=320 h=320 MAX_THREADS=8 MAX_SAMPLES_PER_PIXEL=256
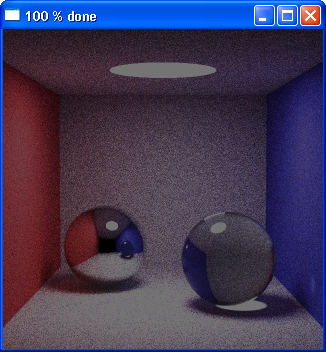
w=256 h=256 MAX_THREADS=1 MAX_SAMPLES_PER_PIXEL=128
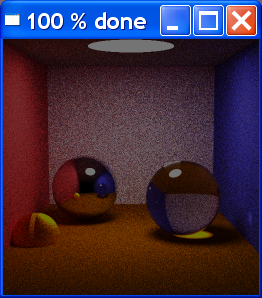
C++ version by kevin beason smallpt: Global Illumination in 99 lines of C++
Code: Select all
const as double M_PI=atn(1)*4
type Vec
declare constructor (a as double=0,b as double=0,c as double=0)
declare function mult(byref b as const Vec) as Vec
declare function norm() as Vec
declare function dot(byref b as const Vec) as double
as double x, y, z
end type
constructor Vec(a as double,b as double,c as double)
x=a:y=b:z=c
end constructor
operator +(l as Vec,r as Vec) as Vec
operator = Vec(l.x+r.x,l.y+r.y,l.z+r.z)
end operator
operator -(l as Vec,r as Vec) as Vec
operator = Vec(l.x-r.x,l.y-r.y,l.z-r.z)
end operator
operator *(l as Vec,r as double) as Vec
operator = Vec(l.x*r,l.y*r,l.z*r)
end operator
operator \(l as Vec,r as Vec) as Vec
operator = Vec(l.y*r.z-l.z*r.y, l.z*r.x-l.x*r.z, l.x*r.y-l.y*r.x)
end operator
function Vec.mult(byref r as const Vec) as Vec
function = Vec(x*r.x,y*r.y,z*r.z)
end function
function Vec.norm() as Vec
this = this * (1/sqr(x*x+y*y+z*z))
return this
end function
function Vec.dot(byref b as const Vec) as double
return x*b.x+y*b.y+z*b.z
end function
type Ray
declare constructor
declare constructor(a as Vec,b as Vec)
as Vec o, d
end type
constructor Ray
d.z=-1
end constructor
constructor Ray(a as Vec,b as Vec)
o=a:d=b
end constructor
enum Refl_t
DIFF, SPEC, REFR ' material types, used in radiance()
end enum
type Sphere
declare constructor (rad_ as double, p_ as Vec,e_ as Vec,c_ as Vec,refl_ as Refl_t)
declare function intersect(byref r as const Ray) as double
as double rad,rad2 ' radius
as Vec p ' position
as Vec e ' emission, color
as Vec c ' color
as Refl_t refl ' reflection type (DIFFuse, SPECular, REFRactive)
end type
constructor Sphere(rad_ as double, p_ as Vec,e_ as Vec,c_ as Vec,refl_ as Refl_t)
rad =rad_ : p=p_ : e=e_ : c=c_ : refl=refl_
rad2=rad*rad
end constructor
function Sphere.intersect(byref r as const Ray) as double
dim as Vec op = p-r.o
dim as double t
dim as double eps=1e-4
dim as double b=op.dot(r.d)
dim as double det=b*b-op.dot(op)+rad2
if (det<0) then return 0
det=sqr(det)
t=b-det : if t>eps then return t
t=b+det : if t>eps then return t
return 0
end function
dim shared as sphere spheres(...) = { _ Scene:
_ ' radius, position, emission, color, material
Sphere(600, Vec(50,681.6-.27,81.6),Vec(32,32,32), Vec(), DIFF), _ 'Lite
Sphere(16.5,Vec(27,16.5,47), Vec(),Vec(.8 ,.8 ,.8 ),SPEC), _ 'Mirr
Sphere(16.5,Vec(73,16.5,78), Vec(),Vec(.8 ,.8 ,.8 ),REFR), _ 'Glas
Sphere(10 ,Vec(10,2 ,90), Vec(),Vec(1,.5,0),DIFF), _ 'Dif
Sphere(1e5 ,Vec(50, 1e5, 81.6), Vec(),Vec(.50,.25,0),DIFF), _ 'Botm
Sphere(1e5 ,Vec(50,40.8, 1e5), Vec(),Vec(1,1,1),DIFF), _ 'Back
Sphere(1e5 ,Vec(50,-1e5+81.6,81.6),Vec(),Vec(.5,.5,.5),DIFF), _ 'Top
Sphere(1e5 ,Vec( 1e5+1,40.8,81.6), Vec(),Vec(.8,.2,.2),DIFF), _ 'Left
Sphere(1e5 ,Vec(-1e5+99,40.8,81.6),Vec(),Vec(.2,.2,.8),DIFF), _ 'Rght
Sphere(1e5 ,Vec(50,40.8,-1e5+170), Vec(),Vec() ,DIFF) _ 'Frnt
}
#define clamp(_x) iif(_x<0,0,iif(_x>1,1,_x))
#define toInt(_x) int(clamp(_x)^1/2.2*255+.5)
function intersect(byref r as const Ray,byref t as double,byref id as integer) as integer
dim as double n=ubound(spheres)
dim as double d
dim as double inf=1e20
t=1e20
for i as integer=0 to n
d=spheres(i).intersect(r)
if(d>0 andalso d<t) then
t=d : id=i
end if
next
return (t<inf)
end function
function radiance(byref r as Ray,depth as integer) as Vec
dim as double t ' distance to intersection
dim as integer id=0 ' id of intersected object
if (intersect(r, t, id)=0) then return Vec(0,0,0) ' if miss, return black
dim as Sphere obj = spheres(id) ' the hit object
dim as Vec x = r.o + r.d * t
dim as Vec n=(x-obj.p).norm()
dim as Vec nl=iif(n.dot(r.d)<0,n,n*-1)
dim as Vec f=obj.c
dim as double p = iif(f.x>f.y andalso f.x>f.z,f.x,iif(f.y>f.z,f.y,f.z)) ' max refl
depth+=1
if (depth>5) then
if (rnd()<p) then
f=f*(1/p)
return vec(1,0,1) 'f
else
return obj.e 'R.R.
end if
end if
' Ideal DIFFUSE reflection
if (obj.refl = DIFF) then
dim as double r1=2*M_PI*rnd()
dim as double r2=rnd()
dim as double r2s=sqr(r2)
dim as Vec w=nl
dim as Vec u= iif(abs(w.x)>.1,Vec(0,1),(Vec(1) \ w).norm())
dim as Vec v=w \ u
dim as Vec d = (u*cos(r1)*r2s + v*sin(r1)*r2s + w*sqr(1-r2)).norm()
return obj.e + f.mult(radiance(Ray(x,d),depth))
elseif (obj.refl = SPEC) then
' Ideal SPECULAR reflection
return obj.e + f.mult(radiance(Ray(x,r.d-n*2*n.dot(r.d)),depth))
end if
' Ideal dielectric REFRACTION
dim as Ray reflRay = Ray(x, r.d - n * 2 * n.dot(r.d))
dim as integer into = (n.dot(nl)>0) ' Ray from outside going in?
dim as double nc=1
dim as double nt=1.5
dim as double nnt=iif(into,nc/nt,nt/nc)
dim as double ddn=r.d.dot(nl)
dim as double cos2t
cos2t=1-nnt*nnt*(1-ddn*ddn)
if (cos2t<0) then ' Total internal reflection
return obj.e + f.mult(radiance(reflRay,depth))
end if
dim as Vec tdir = (r.d*nnt - n*(iif(into,1,-1)*(ddn*nnt+sqr(cos2t)))).norm()
dim as double a=nt-nc
dim as double b=nt+nc
dim as double R0=a*a/(b*b)
dim as double c = 1-iif(into,-ddn,tdir.dot(n))
dim as double Re=R0+(1-R0)*c*c*c*c*c
dim as double Tr=1-Re
dim as double PP=.25+.5*Re
' Russian roulette
if depth>2 then
if rnd()<PP then
dim as double RP=Re/PP
obj.e=obj.e+f.mult(radiance(reflRay,depth)*RP)
else
dim as double TP=Tr/(1-PP)
obj.e=obj.e+f.mult(radiance(Ray(x,tdir),depth)*TP)
end if
else
obj.e=obj.e+f.mult(radiance(reflRay,depth)*Re+radiance(Ray(x,tdir),depth)*Tr)
end if
return obj.e
end function
type threaddata
as any ptr id
as integer w,h
as integer y
as integer samps
as Ray cam
as vec cx
as vec cy
end type
sub RenderThread(byval arg as any ptr)
dim as threaddata ptr td=arg
dim as integer gy=td->h-1-td->y
line (0,gy)-(td->w,gy),rgb(255,0,0)
for x as integer=0 to td->w-1 ' Loop cols
dim as vec c
for sy as integer=0 to 1 ' 2x2 subpixel rows
for sx as integer=0 to 1 ' 2x2 subpixel cols
dim as Vec r
for s as integer=0 to td->samps-1
dim as double r1
dim as double r2
while r1=0:r1=2*rnd():wend
while r2=0:r2=2*rnd():wend
dim as double dx=iif(r1<1,sqr(r1)-1,1-sqr(2-r1))
dim as double dy=iif(r2<1,sqr(r2)-1,1-sqr(2-r2))
dim as Vec d = td->cx*(((sx+.5+dx)/2+x)/td->w-.5) + td->cy*(((sy+.5+dy)/2+td->y)/td->h-.5) + td->cam.d
r = r + radiance(Ray(td->cam.o+d*140,d.norm()),0)*(1./td->samps)
next ' Camera rays are pushed ^^^^^ forward to start in interior
c = c + Vec(clamp(r.x),clamp(r.y),clamp(r.z))*.25
next
next
pset (x,gy),rgb(toInt(c.x), toInt(c.y), toInt(c.z))
next
td->id=0
end sub
'
' main
'
const MAX_THREADS =8
const SAMPLES_PER_PIXEL=64 ' more samples per pixel = higer image quality
dim as integer w=256
dim as integer h=256
dim as string imagefile = "_b" & w & "x" & h & "x" & SAMPLES_PER_PIXEL & ".bmp"
screenres w,h,32
dim as Ray cam=Ray(Vec(50,52,295.6),Vec(0.0,-0.1,-1).norm()) ' cam pos, dir
dim as Vec cx=Vec(w*.5135/h)
dim as Vec cy=(cx \ cam.d).norm()*.5135
dim as double p1=h*0.01
dim as integer i,nThreads
dim as THREADDATA tds(MAX_THREADS-1)
for t as integer=0 to MAX_THREADS-1
for y as integer=t to h-1 step MAX_THREADS
windowtitle "" & int(nThreads/p1) & " %"
dim as integer tind=-1
while tind=-1
if tds(i).id=0 then sleep 10:tind=i:continue while
i=(i+1) mod MAX_THREADS
sleep 5
wend
with tds(tind)
.w=w
.h=h
.y=y
.cx=cx
.cy=cy
.cam=cam
.samps=SAMPLES_PER_PIXEL
end with
if MAX_THREADS>1 then
tds(tind).id=threadcreate(@RenderThread,@tds(tind))
nThreads+=1
else
RenderThread(@tds(tind))
end if
if asc(inkey())=27 then exit for,for
next
next
windowtitle "100 % done "
for i=0 to MAX_THREADS-1
if tds(i).id then
windowtitle "wait " & i & " !"
ThreadWait(tds(i).id)
windowtitle "done ..."
end if
next
bsave imagefile,0
windowtitle "img saved ..."
sleep